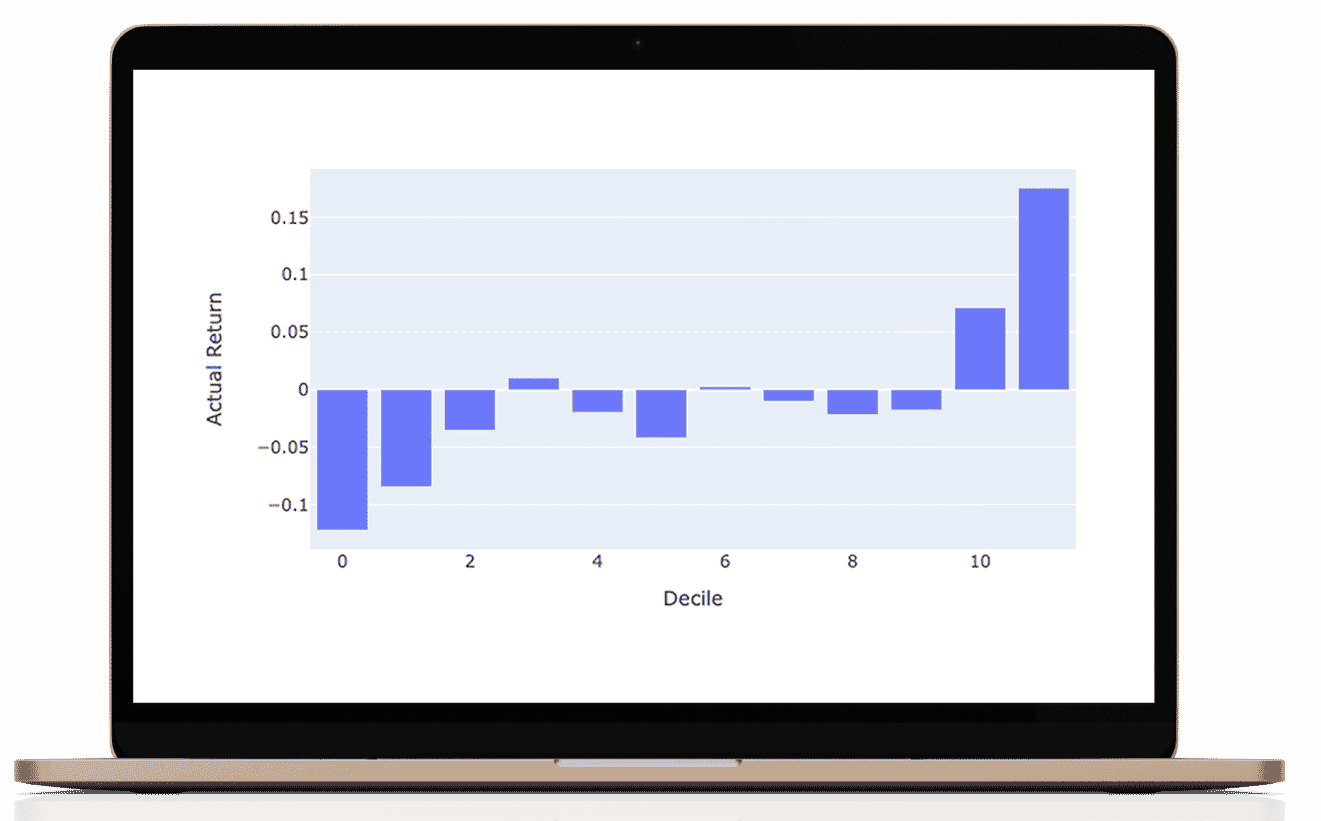
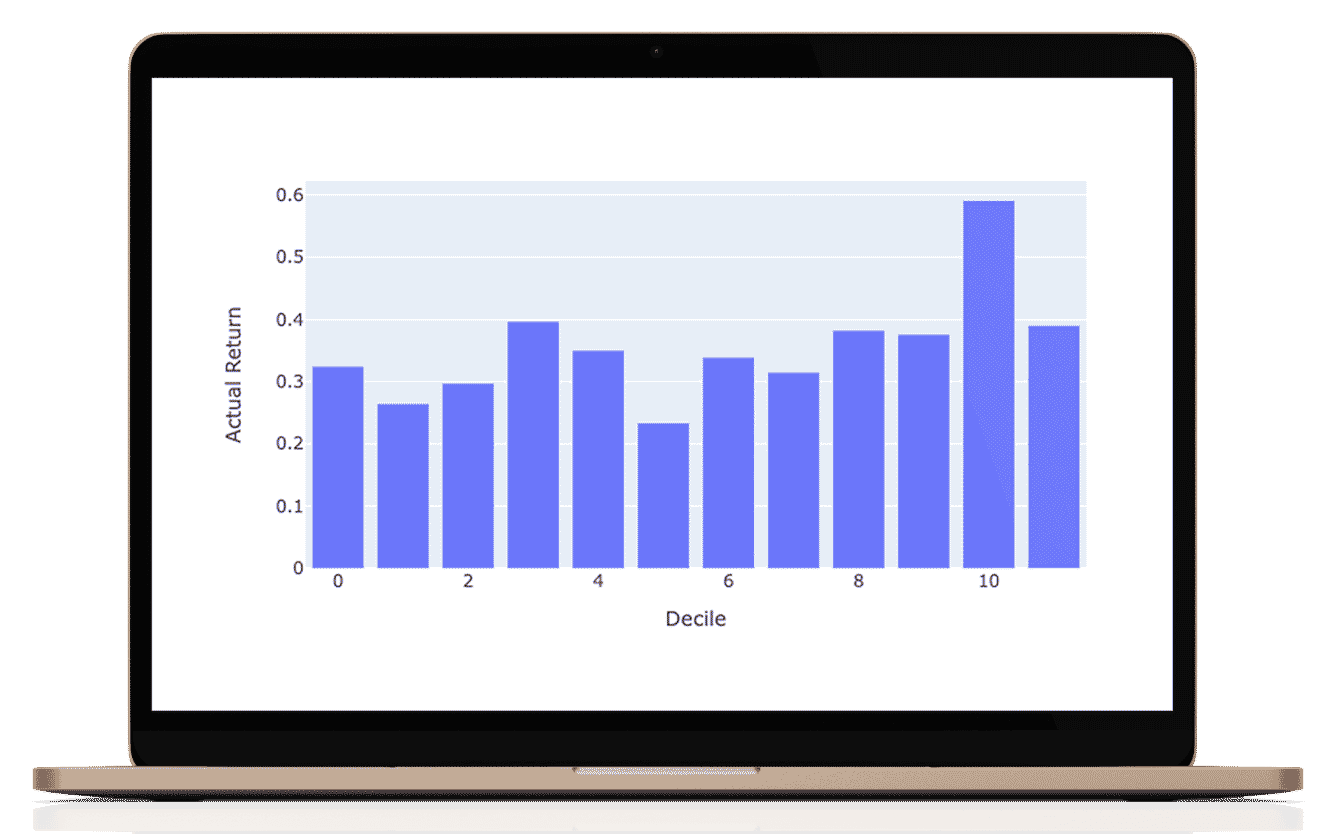
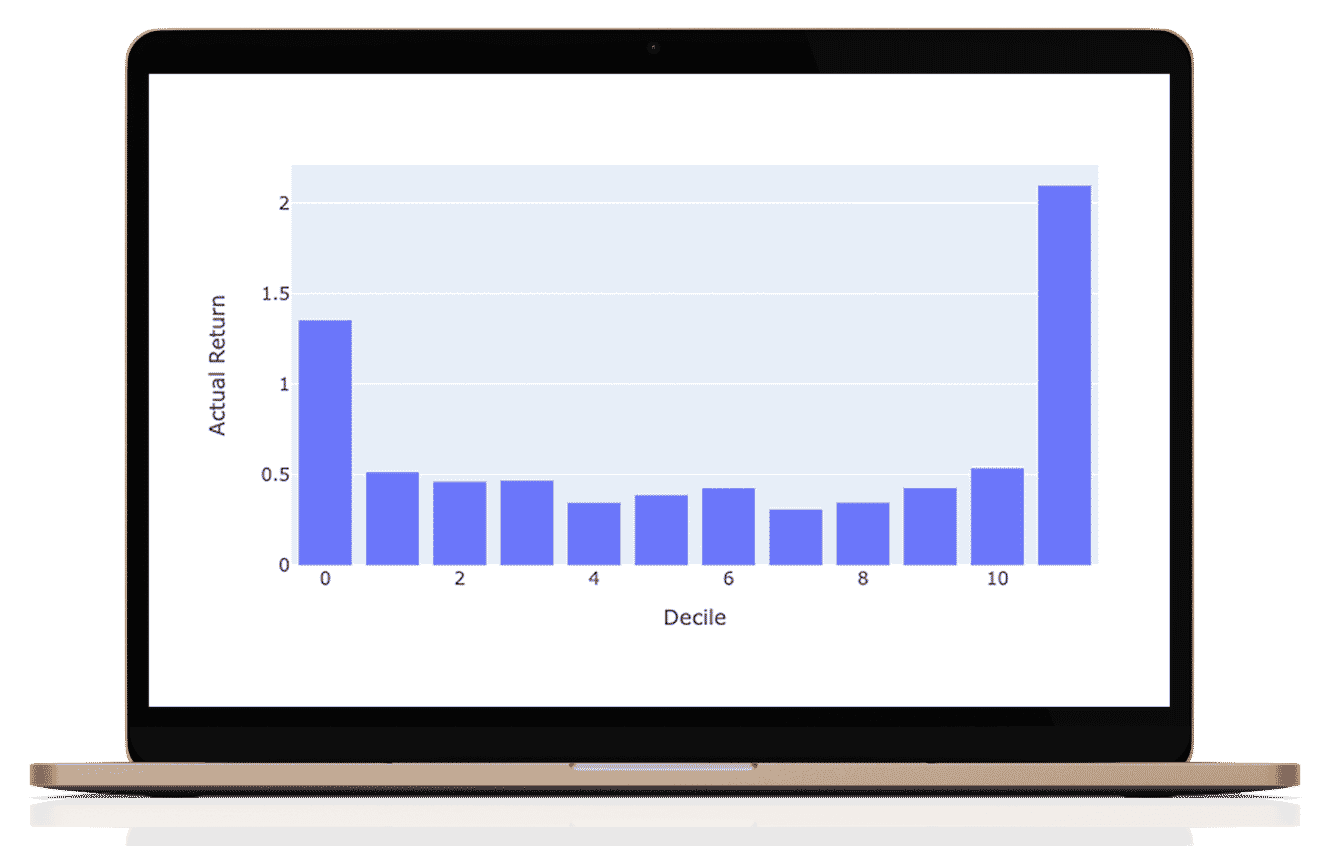
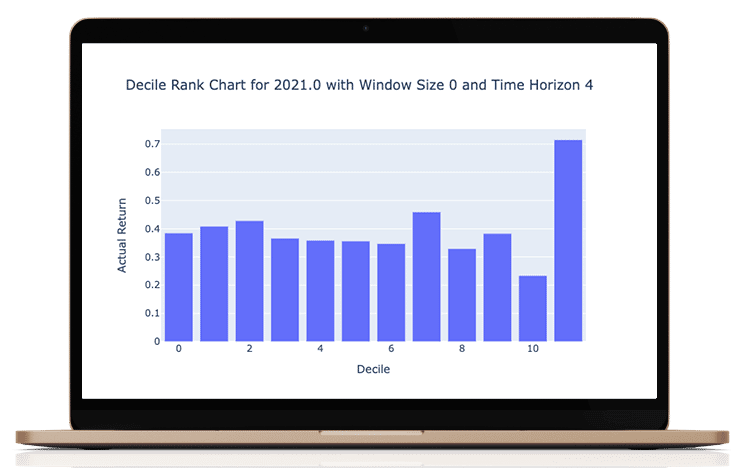
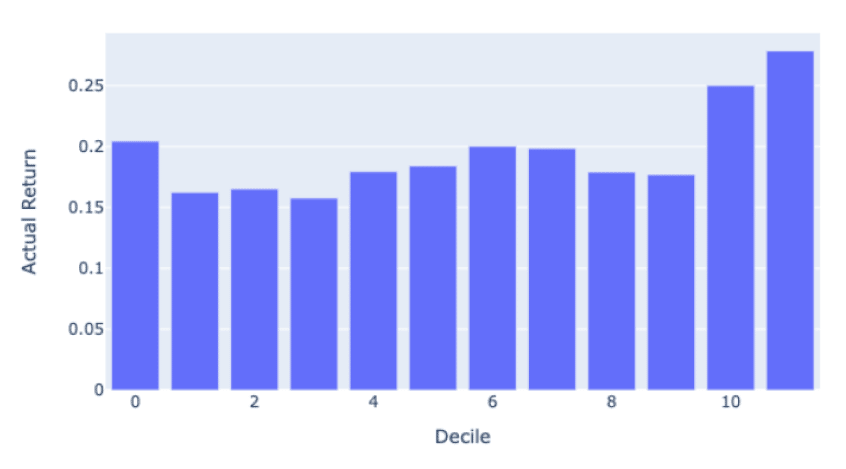
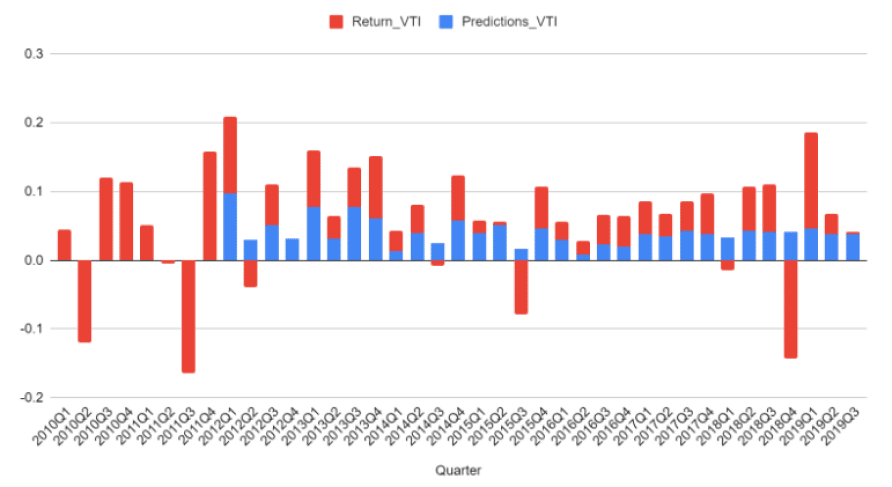
This portfolio or research is hypothetical. This is a historical simulation of the portfolio performance an investor would have obtained had you invested in the same selections at the beginning of the simulation. This report provides information on how the portfolio holdings would have changed and would have performed for a certain period.
We have strived to reduce or eliminate potential biases in the process to provide the most accurate assessment of the performance prospects of the strategy. Because Portfolio ThinkTank offers a significant However, it may not be possible for any historical simulation to completely ensure it is free of all biases.
Please see https://portfoliothinktank.com/the-gold-standard-for-portfolio-backtesting/ and https://portfoliothinktank.com/the-seven-deadly-sins-of-portfolio-backtesting/ for a more complete understanding of biases and risks when backtesting portfolio strategies.
Backtested strategies also run the risk of cherry picking. Cherry Picking is when the author of the backtest has created many variations and is presenting one of the variations that is more favorable. This research was not produced in whole or in part by cherry picking.
This simulation is based on an account with tax exempt or tax deferred growth. Taxable accounts will have to pay the appropriate taxes for dividends, interest and capital gains, which will decrease the performance depicted.
This simulation is not based on actual trading accounts or account composites which may or may not exist for this strategy and may be materially different including worse than the performance illustrated above. Past performance is not necessarily indicative of future performance. Performance results including risk, return and diversification measures are not guaranteed to persist in the future.
This historical performance simulation has been adjusted to reflect estimated management fees.
The suitability of this portfolio strategy requires that you have thoughtfully and accurately completed your investor objectives from your accounts’ Investment Policy Statement. https://portfoliothinktank.com/portfolio-think-tank-login/
Diversification strategies alone cannot assure a successful investment outcome. Strategies offering greater diversification cannot guarantee any reduction in loss of capital.
Your ability to follow this investment strategy is a risk. Investors often dispose of successful strategies at inopportune times thus turning potentially profitable strategies into losses.
Portfolio data is taken from sources believed to be accurate, however, there is no warranty or guarantee as to the accuracy or completeness of data and statistical calculations thereupon. Our performance results are not audited or otherwise approved by any regulatory agency. We regularly perform quality and accurate tests on our calculation and algorithmic procedures. Portfolio ThinkTank does not furnish investment advice without an investment advisory agreement.
The period of time selected for analysis may have a significant bearing on the relative attractiveness of the strategy and the strategy versus another portfolio or benchmark. The author of the strategy controls the default period of time used to analyze performance and from there, users may select any desired period of time from the menu. In general, longer periods, greater diversification and lower concentrations of holdings result in more credible, more persistent performance.
We are unaware of any errors at the time of writing.